
جميعنا نعلم أن معالجات Haswell وسوابقها من معالجات Ivy-Brdige تستطيع أن تقدم 16 ممر – Lanes- فقط لمنافذ البطاقات الرسومية
وهو ما يحد من قدرة البطاقات على إخراج كامل قوتها. فلا نستطيع تركيب أكثر من ثلاث بطاقات بسرعات x8/x4/x4 من منافذ الجيل الثالث PCI-E 3.0.
ولكن الحال يختلف بإضافة شريحة PLX PEX 8747 – وهى محور حديثنا اليوم – و التي باستطاعتها أن توفر حتى 32 ممر PCI-E 3.0 وهو عدد كافى لتركيب 4 بطاقات رسومية
تعددية البطاقات مع منصة Z87
و هي وضعيات موجهه للمستخدمين المتحمسين ذوي الميزانيات الضخمة حيث وضعيات 4-Ways أو 3-Ways ليمكنهم من تشغيل عدة شاشات مع بعض بدقة عالية بهدف تجربة فريدة من اللعب السلس أو لأقصى أداء ممكن بشاشة واحدة ذات دقة عالية, فهؤلاء المستخدمون لا يكفي إحتياجاتهم معالج رسومي واحد بحيث يسعون إلى كل ماهو جديد, و بالطبع الكثير منهم يستخدم التبريد المائي و ووحدات طاقة power supply عالية الكفاءة وفى بعض الحالات يتم إستخدام وحدتي طاقة لتغطية إستخدام الجهاز من الكهرباء.
أولئك المستخدمون يتطلعون إلى أقوى وأسرع عتاد للهاردوير, وإن سألت أحدهم من قبل بضع سنين ماضسة عن أى منصة تناسب تعدد البطاقات الرسومية 4-ways, فمن المؤكد سيفكر فى منصة X79 ومعالجاتها Sandy Bridge Extreme و ذلك لقدرة معالجاتها على توفير 40 ممر لكروت الشاشة والكافى جدآ لتركيب أربع بطاقات بإرتياح.
ولكن الجانب السلبى هو أن البطاقات ستعمل على المنفذ PCI-E من الجيل الثانى المحدود بعرض نطاق Bandwidth قدره 8GB/s فقط, فسنواجه مشكلة جديدة تعيق تلك العملية وهى عنق الزجاجة . فالأربع بطاقات تحتاج إلى عرض نطاق ترددى واسع بين الذاكرة ومنفذ الPCI-E . فالحل هنا هو الإنتقال إلى الجيل الثالث PCI-E 3.0 ذا العرض النطاق الترددى الأوسع حتى الآن بقدر 16GB/s وهو مايمثل ضعف عرض النطاق للجيل السابق.
تلك المعضلة التى ربما تم حلها مع صدور معالجات IVY Bridge Extreme. ولكن دعنا نتحدث قليلآ عن معالجات ال MainStream و تعددية البطاقات حتي أربع بطاقات.
المشكلة الأخرى التى ستواجهنا هى أنه عند الإنتقال إلى المعالجات العادية سنجد دعم ل16 ممر فقط مما يحجمنا مرة أخرى إلى ثلاث بطاقات مرة أخرى التى يستطيع تلك المعالجات توفيرها كما نرى فى المخطط التالى.
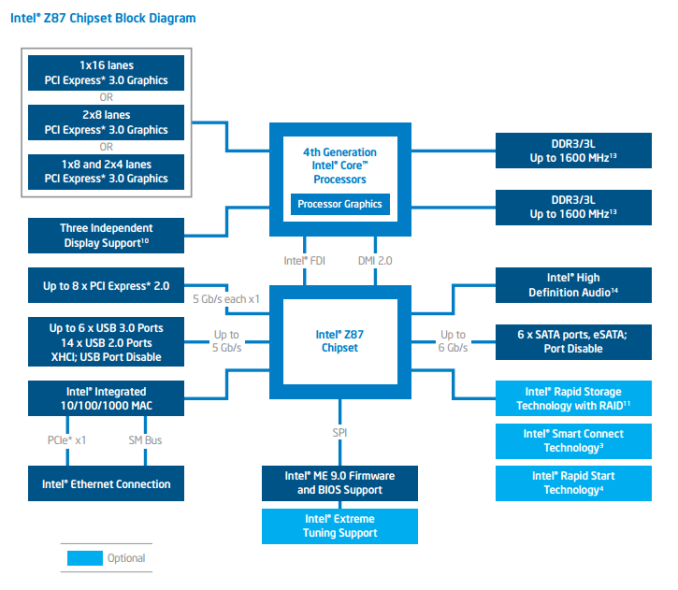
ويمكن تقسيم ال16 ممر كما يوضح الجدول التالى
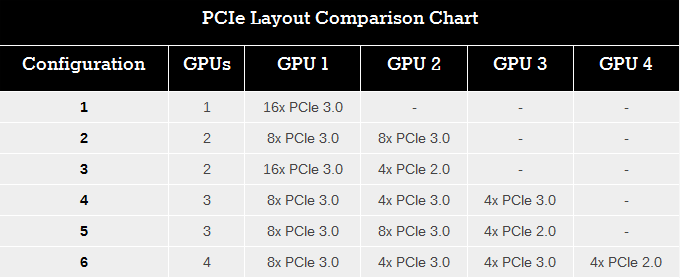
نري أحد تلك الوضعيات استطاع مصنعى اللوحات الأم أن يوفروه باستخدام الأربع مسارات PCI-E 2.0 القادمة مباشرة من المعالج لوضعيات الكروسفاير ( SLI لاتدعم تلك الوضعية لأن بطاقات Nvidia لا تدعم وضعية x4 الآن )
فلو أخذنا اللوحات الأم MINI-ITX على سبيل المثال, فسوف نرى الوضعية الأولى ذات المعالج الرسومي الواحد . فى اللوحات الأم ذات الحجم Micro-ATX سوف نرى الوضعيات ذات المعالجين الرسوميين (2ways) وهى الوضعيات المرقمة ب 2 , 3 فى الجدول السابق .. وفى اللوحات ذات الحجم الكامل Full-ATX سوف يتاح لنا أى وضعية كانت.
ولكن الوضعيات الأساسية هنا ذات الإنتشار الواسع هى ذات الأرقام 1,2,4,5.
بالعودة إلى الوراء قليلآ بالتحديد إلى زمن الشرائح X58 , P55 حيث كانت PCI-E 2.0 تسيطر على المشهد , حيث ظهرت الشريحة NF200 التى كانت تسمح لللوحة الأم أن تضايع حصتها من ممرات الPCI-E 2.0 من 16 ممر فقط إلى 32 ممر والتى كان لها عدة جوانب سلبية تتمحور حول سعرها المرتفع والذى قد يضاعف سعر اللوحة الأم وإستهلاك الطاقة المرتفع وزيادة الحمل على المعالج
عدة سنوات إلى الأمام ونصل حتى نمتلك شريحة أخرى تحت مسمي PEX 8747 و التى تهدف لنفس الهدف ولكن مع منافذ PCI-E 3.0 وتحاول أن تتجنب الجوانب السلبية فى سابقتها . تلك الشريحة PLX PEX التى تقدم إستطاعة التحويل بين منافذ الPCI-E , فعند إستخدامها سنتجاوز عقبة ال16 ممر فنصل إلى 32 ممر لتمكننا من زيادة عدد الوضعيات والتى يوضحها الجدول التالى :
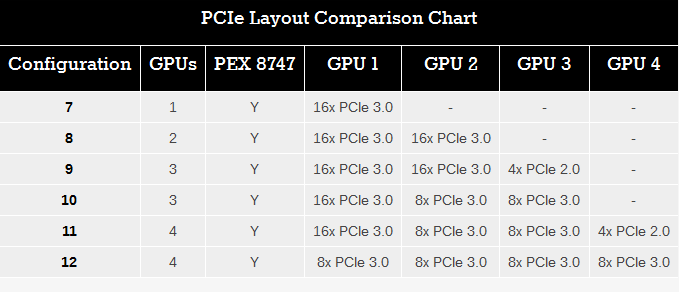
والآن نحن حصلنا على 32 ممر PCI-E 3.0 ذات النطاق الترددى الواسع بدلآ من 40 ممر PCI-E 3.0 التى تقدمها منصات X79
كيف تعمل تلك الشرائح ؟
“هذا الجزء من المقال تقنى بحت فيتوجب عليك عزيزي القارئ أن تكون فى كامل صفاء الذهن حتى لا تشعر بدوار أو صداع :)”
بداية لتسهيل تلقى المعلومة فإني أود أن أوضح حقائق هامة قبل البدء , تتخلص فى أن البيانات تنتقل من المعالج المركزي CPU إلى المعالجات الرسومية GPU فى ممرات وكما نعلم أن فى نهاية تلك الممرات هي شقوق الPCI-E وتلك الشريحة -أو مثيلتها من تلك الشرائح- توضع بين المعالج المركزي CPU ومنافذ PCI-E 3.0 وتتحكم بتلك الممرات و سرعاتها.
الإرتباك الموجود أو الضبابية حول تلك الشريحة عند بعض الناس هو أنه عدد الممرات القادمة من أو الى فلا يهم عدد الممرات بين المعالج وتلك الشريحة فتلك الممرات لا تزال 16 ممر فقط بين المعالج والرقاقة ولكن السر فى التعامل ما بعد الرقاقة وبينها وبين شقوق التوسعة لنقل البيانات ويسبب دائمآ عنق الزجاجة فكيف إذن نحصل على 32 ممر ؟
أمر محير ولكن إن شاء الله إذا أكملت سوف تستطيع أن تدرك تلك المعضلة فرأيت العديد من المنتديات والمواقع تتحدث عن أن تلك الشريحة تضاعف عدد الممرات إلى 32 وتلك الإجابة تحمل فى طياتها الخطأ
فعند البحث عن تلك البيانات وجدنا العديد من المواقع تتكلم كثيرآ ولكن المعلومات التقنية قليلة فتفقر المقالات إلى التقنية . لكن الموقع الرسمي لشركة PLX يحتوي على العديد من المعلومات والبيانات التى توفر لك الفهم الصحيح وبالتالى أنا أحاول أن أشرح على قدر إستطاعتى تلك المعلومات
الهدف من شريحة الPLX هو إدارة الشريحة للبيانات بين وحدة المعالجة المركزية و منافذ الPCI-E 3.0 . وهى تقوم بالإدارة عن طريق المضاعفة أو بمعنى آخر فن التعامل مع الإشارات المتعددة التى تريد الإنتقال من نقطة واحدة فقط وإليكم بعض أساسيات المضاعفة :
– مضاعفة الإشارة : الجمع بين عدة إشارات تنظارية داخل إشارة واحدة وتهيئتها لنقلها دفعة واحدة إلى الجانب الآخر سواء من الCPU إلى الPCI-E3.0 أو العكس وفى الجانب الأخر يتم إعادة هيئتها إلى إشارات فردية ليتم فكها للحصول على البيانات الأصلية . يتم إستخدام تلك الطريقة على نطاق موسع من الإتصالات السلكية واللا سلكية
– مضاعفة تقسيم الوقت : بدلآ من إقامة عدة إتصالات مرتفعة السرعة بين نقطتين موجود فى كل نهاية عدة مستخدمين يتم تثبيت إتصال واحد ويتولى هذا الخط إقامة الإتصالات بين كل زوجين من المستخدمين بحيث لا تتعطل الإشارة دون قصد … يتم شرح تلك النقطة فى الصورة القادمة :
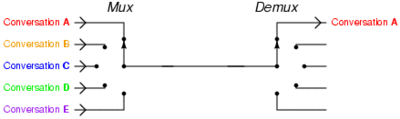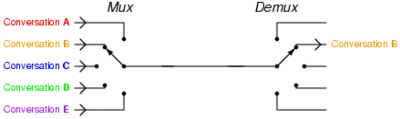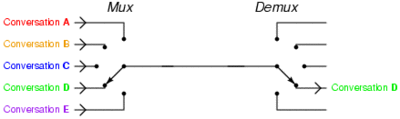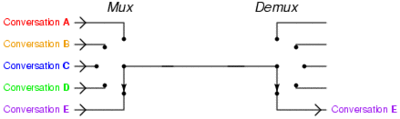
إذن كيف تعمل تلك الرقاقة ؟ التفسير الأفضل لتلك العملية هو أنها تعمل على المضاعفة السابق شرحها مع وجود وحدة تخزين مؤقتة (buffer) وتنظم البيانات بسياسة FIFO إختصارآ ل First in , First Out . دعونا نعطى مثالآ وليكن أبسط مثال , عندما تعمل شريحة الPLX مع معالجين رسوميين والإثنين يعملان على سرعة x16
شريحة الPLX تسمح للمعالج والذاكرة بالوصول لعناوين أو أماكن المعالجات الرسومية المربوطة بها , حيث يقوم المعالج بإرسال البيانات إلى المعالج الرسومي الأول فقط ولا يقوم بإرسال أى بيانات الى الكرت الثانى إن لم تستدعي الحاجة, فتقوم الشريحة بتحويل كل المسارات إلى المعالج الرسومى الأول وبعدها يقوم المعالج بإرسال البيانات إلى المعالج الرسومي الثانى فتحول الشريحة مرة أخرى كل الممرات إلى المعالج الرسومي الثانى
ماذا عن لو افترضنا أن البيانات يجب أن ترسل إلى الإثنين معآ بطريقة تزامنية أو في وقت واحد ؟؟ حسنآ لنوضح الأمور قليلآ … المعالج يستطيع أن ينقل البيانات إلى الشريحة ب 16 مسار فقط .. فهناك إحدى الطرق التى ستفعلها الشريحة إذا تم الإرسال للمعالجين الرسوميين فى وقت واحد إما أن تنقل كل الداتا إلى المعالج الرسومي الرئيسي (الأول) وهو يتولى مأمورية نقلها إلى المعالجات الرسومية الأخرى أو أن تختار الشريحة فى تقسم الخطوط بين المعالجات الرسومية المطلوبة فى وقت واحد بالتساوى أو على حسب نسبة البيانات المنقولة إليه فالمعالج الرسومي ذا الحصة الأكبر من البيانات تتوفر له الحصة الأكبر من الممرات
هذا يعنى أن فى حالة تواجد بطاقتين , فى أقصى قوتهما , نحن لا نزال محددين بـ x8/x8 , ولكن فى حالة معالج رسومي واحد طلب البيانات فستستطيع الرقاقة أن تخصص جميع الممرات ال16 لتلك البطاقة . و إذا إنتقلت البيانات من المعالج الرسومي إلى المعالج المركزي تستطيع الرقاقة أن ملأ الذاكرة المؤقتة Buffer بكامل السرعة x16 لكل معالج رسومي , وفى الوقت نفسه ترسل الرقاقة البيانات بأسرع سرعة ممكنة للمعالج المركزى على هيئة دفق مستمر بسرعة x16 بدلآ من التبديل بين كل معالج على حدى واللذى من الممكن أن يؤخر البيانات بعض الشئ في وقت لا يتجاوز المايكرو من الثانية
إنها خاصية مفيدة حقآ. فبدون تلك الشريحة, ستمتلك وحدات المعالجة الرسومية عدد ثابت من الممرات التى يمكن تعديلها فقط للتقسيم بين الشقوق PCI-E عند إضافة بطاقات رسومية أخرى, وهذا يعنى أنه فى حالة وجود معالجين رسوميين ولكلاهما عدد 8 ممرات فقط فإنه حتى لو طلب معالج رسومي واحد البيانات فسوف تنتقل فى تلك ال 8 ممرات فقط كحد أقصى.
العودة للوراء قليلآ مرة أخرى إلى أيام NF200 والمعاناة مع زيادة الحمل 1-3% فى العديد من المقارنات , شريحة PLX PEX 8747 تحاول أن تتلافى هذا الحمل الزائد وخاصة أنها قادمة خصيصآ للظروف القاسية من وضعيات أبرع بطاقات .
لنأخذ مثالآ على تلك الشريحة ولتكن اللوحة الأم Gigabyte G1 Sniper 3 . تلك اللوحة الأم توجه كل ممرات ال PCI-E3.0 من الCPU عبر شريحة PEX 8747 . وتوزع الممرات حسب المخطط التالى :
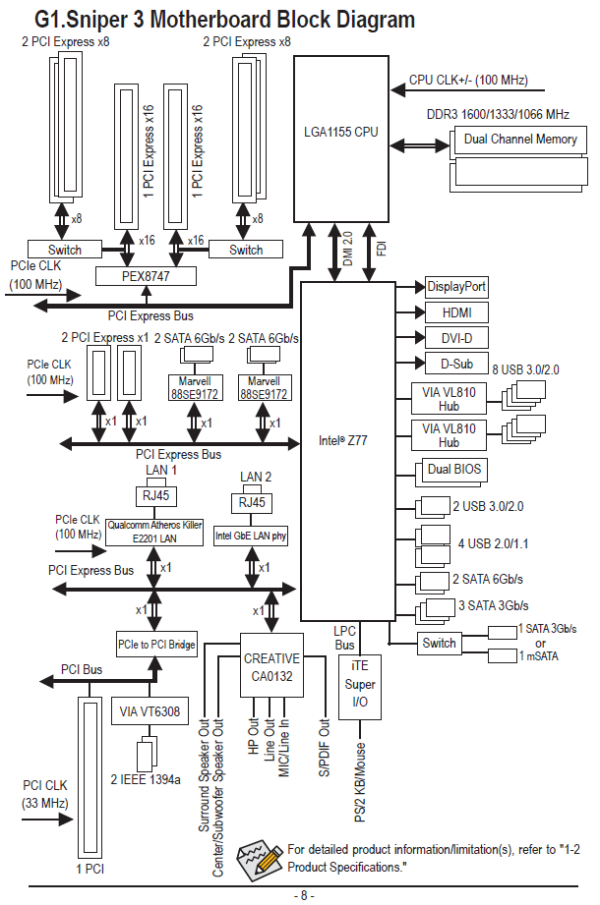
من خلال هذا المخطط يمكننا أن نرى أن الشريحة توجه ممرات PCI-E 3.0 x16 إلى معالج رسومي و أخرى إلى المعالج الرسومي الآخر . وينبغى أن يتم إدخال البطاقات الأخرى أسفل تلك البطاقات الأساسية . وبعد ذلك يتم تقسيم الممرات الستة عشر إلى x8/x8 إستنادآ على عدد المعالجات الرسومية الموجودة . بعد ذلك تقرر الشريحة PEX 8747 عرض النطاق – Bandwidth – المناسب بالنظر إلى خيارات الممرات المتاحة والبيانات ذات الأولوية من خلال المضاعفة و المخزن المؤقت FIFO Buffer الموجود على الشريحة . الجانب السلبى هنا هو فى حالة تركيب معالج رسومى واحد فقط فتؤدى الشريحة PEX إلى بعض التأخر فى وصول البيانات حيث أن الشريحة تقف بين المعالج وشقوق الPCI-E التى يمكن أن تقلل من أداء بطاقة واحدة, و لكن و على كل حال هذا التأخير لن يتجازل الميكرو من الثانية الواحدة فقط.
هناك حل أيضآ لتلك المعضلة مع توجيه الممرات وتقسيمها من وحدة المعالجة المركزية CPU . كما موجود على اللوحة EVGA Z77 FTW . فتوجه تلك اللوحة 8 مسارات PCI-E إلى الشق الأول دون المرور بأى شرائح . والثانية هو بتوجيه الممرات إلى شريحة الPEX 8747 . وتستخدم تلك الطريقة على النحو اللذى يوضحه المخطط التالى :
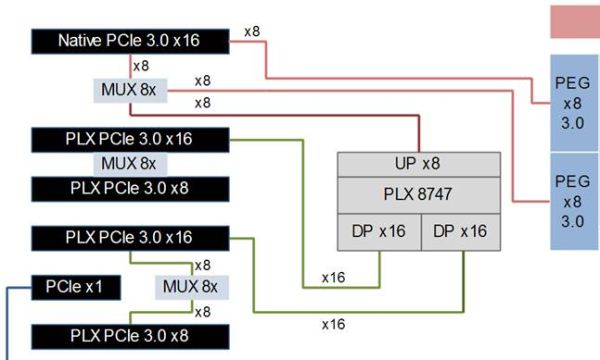
فى تلك التوزيعة يقسم المعالج المركزي ممراته الـ 16 إلى قسمين , الثمان ممرات الأولى توجه إلى الشق PCI-E الأول مباشرة دون المرور بأى شرائح . والقسم الثانى يوجه إلى شريحة PEX 8747 التى تستطيع أن تفعل بهم 32 ممر ب 4 شقوق PCI-E * لاحظ أن الشق الثالث لن يستخدم فى حالة تعدد البطاقات فتصبح فعليآ الشريحة تتحكم بثلاث شقوق فقط أو أقل عند تعدد البطاقات
وهذا يعنى أن الشقوق من الثانى إلى الرابع حتى إن كانت تعمل ب16 ممر لكل منهم فهى ستحدد إلى 8 ممرات فقط عند إنتقال البيانات إلى المعالج المركزي CPU . EVGA صرحت قائلة بأن تلك التقسيمة تعطى أداء أفضل عند وجود بطاقة واحدة أو إثنين عن معظم المصنعين الآخرين . فمعظم الإتصالات بين المعالجات الرسومية وبعضها تتم عن طريق جسور الSLI/CFX ولن تكون محددة ب8 ممرات فقط, وشريحة الPLX ذكية بقدر كبير تمكنها من إغلاق الممرات الغير مستخدمه وتوزيعها مرة أخرى وتوفير الطاقة
وتلك التقسيمة التى وضعتها لنا EVGA تسمح لنا بوضعيات أخرى يوضحها الجدول التالى :
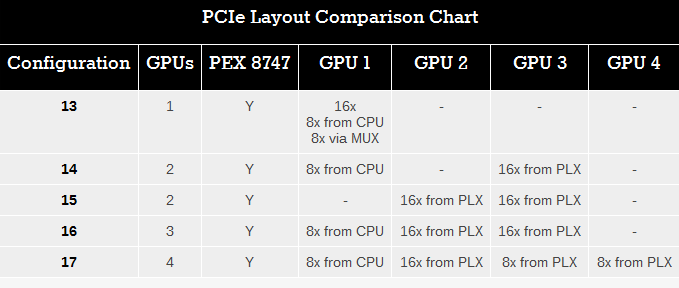 *الفرق بين الوضعين الرابع والخامس عشر يتلخص فى أنه بالرغم من أن ممرات الواضع الخامس عشر للمعالج الرسومي الأول ستكون أكثر لكنها ستضيف بعض التأخير لكون المعالج الرسومي الأول ممراته تتمر عبر شريحة الPLX أولآ . فالوضع الرابع عشر يمد المعالج الرسومي بممرات عددها 8 فقط ومع ذلك سيكون أسرع.
*الفرق بين الوضعين الرابع والخامس عشر يتلخص فى أنه بالرغم من أن ممرات الواضع الخامس عشر للمعالج الرسومي الأول ستكون أكثر لكنها ستضيف بعض التأخير لكون المعالج الرسومي الأول ممراته تتمر عبر شريحة الPLX أولآ . فالوضع الرابع عشر يمد المعالج الرسومي بممرات عددها 8 فقط ومع ذلك سيكون أسرع.



